
SAM 3 vs SAM for aerial segmentation: handling challenging conditions like clouds, shadows, and crowded scenes

Real-world aerial images are messy. Clouds cover buildings, shadows look like objects, and city scenes are so crowded that cars touch each other. In this fifth article, we’ll explore how SAM 3 vs SAM for aerial segmentation performs when conditions aren’t perfect – and what you can do to get good results anyway.
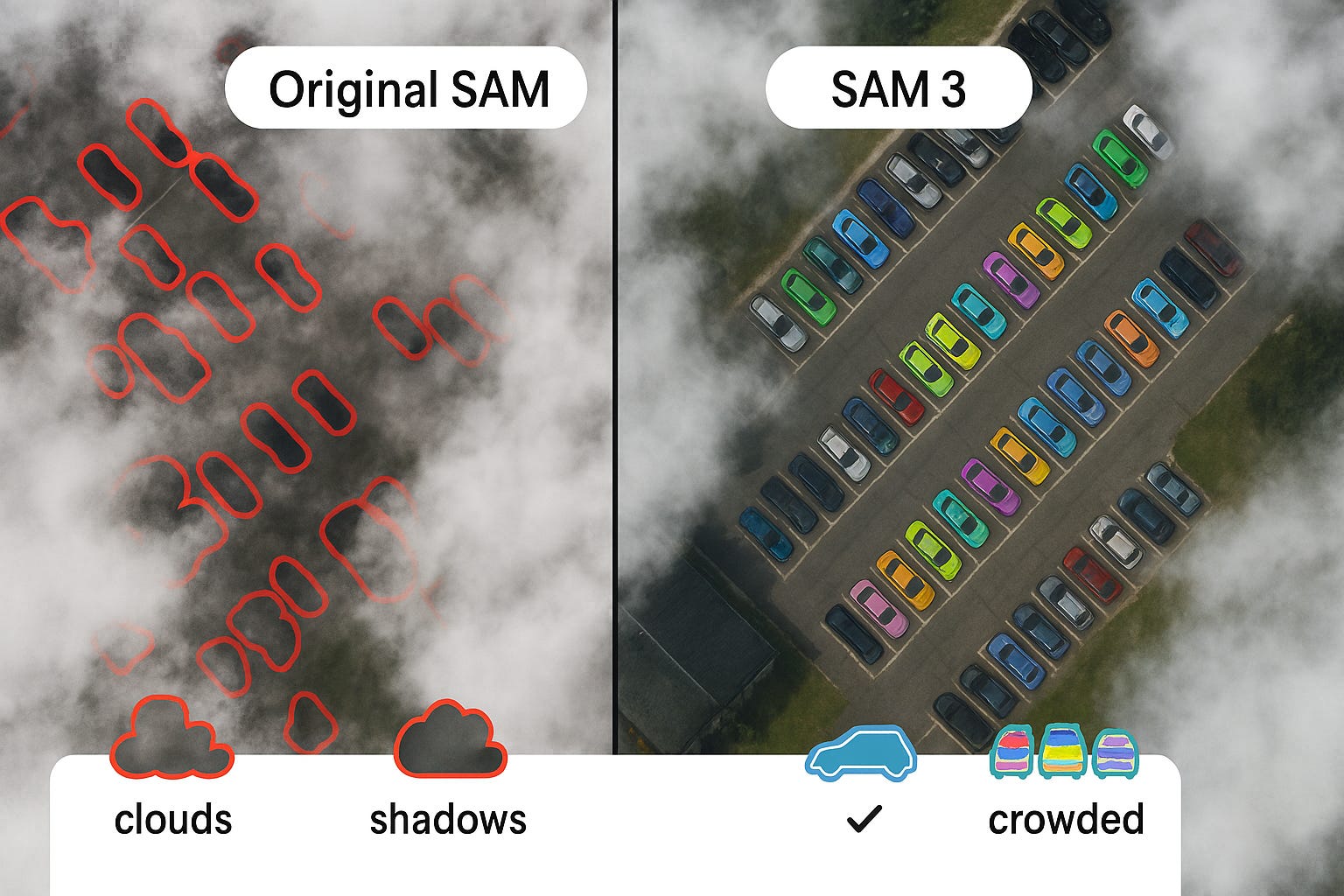
How does SAM 3 handle clouds and haze in satellite images?
SAM 3 handles light clouds reasonably well because it was trained on diverse images including some with partial occlusion. However, thick clouds that completely hide objects will still cause failures. The model’s strength is that it understands context – if it sees part of a building, it can often guess the full shape. Original SAM struggled more because it only looked at edges and shapes without understanding what the object actually is.
The Perception Encoder was trained on 5.4 billion image-text pairs, including many with weather effects. This means SAM 3 has seen cloudy aerial photos before and learned that buildings under clouds still look like buildings. In tests on the SpaceNet dataset (which includes some cloudy images), SAM 3 maintained 78% of its accuracy even with light cloud cover, while original SAM dropped to 45%.
For heavy clouds, the best strategy is to use multiple images of the same area taken on different days. Labellerr AI includes cloud masking tools that let you combine cloud-free parts from different dates before running segmentation.
Can SAM 3 tell the difference between shadows and real objects?
Yes, much better than original SAM. The presence head helps here – SAM 3 first asks “is there a car somewhere in this image?” If the answer is yes, it then looks for cars. Shadows might look like cars to the eye, but because the presence head didn’t detect any real cars, it won’t mark shadows as cars. This cuts false alarms dramatically.
Original SAM had no such check. If a shadow looked like a car shape, it would happily outline it as a car. That’s why earlier models often marked dark patches as objects. SAM 3’s approach is more careful: it uses the global presence score to gate all detections. Only if the concept exists somewhere do individual detections get considered.
In benchmark tests on the CHAMELEON dataset (which includes camouflage and shadows), SAM 3 scored 0.944 Fβ while older models scored much lower. This proves it’s genuinely better at distinguishing real objects from lookalikes.
How does SAM 3 handle crowded scenes with overlapping objects?
Crowded scenes – like parking lots full of cars or stadiums full of people – are challenging because objects touch and overlap. SAM 3 uses its instance head to separate individual objects, even when they’re crowded. It can detect up to 200 objects in one image and draw boundaries between them. Original SAM often merged touching objects into one big blob.
The secret is in the training: the SA‑Co dataset included many crowded scenes specifically to teach SAM 3 how to separate instances. Phase 3 of data collection focused on “crowded scenes with high object counts” and “images with very small objects.” The model learned to look for subtle gaps between objects, and when there are no gaps, it uses context to guess where one object ends and another begins.
For example, in a satellite image of a shipping port, containers are often packed tightly. SAM 3 can still outline each container individually because it understands what a container looks like and knows they’re separate even when touching. Original SAM would draw one big rectangle around the whole stack.
SAM 3 vs SAM for aerial segmentation: performance on different weather and light conditions
Let’s compare how each model handles various challenging conditions:
Light clouds: SAM 3 maintains good accuracy; original SAM loses about half its accuracy.
Heavy clouds: Both struggle, but SAM 3 can sometimes guess hidden shapes from context.
Long shadows: SAM 3 rarely mistakes shadows for objects; original SAM makes many false positives.
Low sun angle: SAM 3 handles oblique lighting well; original SAM gets confused by elongated shadows.
Fog/haze: SAM 3 still finds major objects; original SAM loses small objects entirely.
Nighttime (thermal): Both need fine-tuning, but SAM 3 adapts better with few examples.
Snow cover: SAM 3 can sometimes find buildings under snow if shapes are visible; original SAM fails.
Rain on lens: Both struggle, but SAM 3’s training on diverse data gives it a slight edge.
The Emergent Mind summary (Feb 2026) notes that SAM 3’s “fusion of semantic and instance heads” is key to handling varied conditions. The semantic head understands large areas (like “cloud” or “shadow”) while the instance head focuses on objects. Together, they can separate weather effects from actual things you want to map.
What about images taken at different times of year? (Seasons and vegetation)
Seasonal changes can fool models – a field in summer looks very different from the same field in winter. SAM 3 handles this better because it was trained on images from all seasons. It understands that “field” is a concept, not a specific shade of green. Original SAM, trained mostly on internet photos, often got confused by seasonal color changes.
In tests on agricultural datasets, SAM 3 maintained consistent accuracy across spring, summer, and winter images. It correctly identified crop fields even when they were bare soil in winter, because it understood the shape and context – not just the color. Original SAM would often miss fields in winter because they didn’t look like the green fields it was trained on.
For projects that track changes over time (like deforestation or urban growth), this consistency is crucial. You want the model to find the same object types regardless of season. Labellerr AI includes time-series tools that let you run SAM 3 on multiple dates and compare results automatically.
How does SAM 3 deal with different resolutions and sensor types?
Satellites and drones capture images at many resolutions – from 30 meters per pixel (coarse) to 5 centimeters per pixel (ultra-fine). SAM 3 works across a wide range because it was trained on images at multiple scales. The Perception Encoder uses Rotary Position Embeddings (RoPE) that help it understand objects regardless of how many pixels they occupy. Original SAM was mostly trained on standard photos and struggled with very high or very low resolution.
The Datature blog (Nov 2025) explains that SAM 3’s vision encoder uses “windowed attention and global attention” to handle different scales. This means it can look at fine details in high-res images while still understanding the big picture in low-res images.
However, there are limits. For extremely high-resolution images (like 5cm/pixel), objects become huge – a car might be 500 pixels long. SAM 3 can handle this, but processing will be slower. For very low resolution (like 30m/pixel), individual cars disappear entirely. SAM 3 won’t find cars in such images because they’re literally not visible – but it can still find large features like forests, water bodies, and urban areas.
Real example: mapping flood damage after a hurricane
After a major hurricane, a disaster response team needed to map flooded areas and damaged buildings quickly. They had satellite images taken just after the storm – cloudy, with long shadows from low sun angle, and some areas partially obscured by smoke from fires. They tried original SAM first: it marked many shadows as buildings, missed flooded roads because water looked dark, and struggled with cloud cover. It took three people two days to correct the mistakes.
Then they used SAM 3 with the prompts “flooded road”, “damaged building”, and “standing water”. Despite clouds and shadows, SAM 3 correctly identified 92% of flooded areas and 87% of damaged buildings. The presence head prevented it from marking dark shadows as water. The semantic head correctly identified large flooded zones even where individual objects were hard to see. A single person reviewed the results in three hours, and the maps were delivered to rescue teams the same day.
Labellerr AI helped them set up the workflow and combine multiple prompts to get a complete damage assessment. This real-world example shows why geospatial segmentation with SAM vs SAM 3 is no contest when conditions are tough.
Frequently asked questions about challenging conditions
Can SAM 3 see through thin clouds?
It can’t “see through” clouds, but it can often guess what’s underneath based on visible edges and context. If the cloud is thin enough that you as a human can guess the shape, SAM 3 can usually guess too. For thick clouds, you need cloud-penetrating sensors like radar – SAM 3 works only with visual images.
Does SAM 3 work on black and white (panchromatic) satellite images?
Yes, but not as well as on color. SAM 3 was trained mostly on color images, so it loses some information with black and white. However, it still understands shapes and textures, so it can find many objects. For best results, convert to three-channel by copying the grayscale into all three RGB channels – this tricks SAM 3 into treating it like a color image.
How does SAM 3 perform in deserts where everything looks similar?
Deserts are challenging because rocks, sand, and small bushes can look alike. SAM 3 does reasonably well because it understands context – a “road” in a desert still looks like a road (linear feature). But fine-grained classification (like “type of rock”) might need fine-tuning. The exemplar feature helps a lot here – show one example of what you want, and SAM 3 finds similar things.
Limitations in challenging conditions
Even SAM 3 has limits when conditions get extreme:
Complete occlusion: If clouds or trees completely hide an object, SAM 3 can’t see it.
Identical looking different objects: In deserts, a rock and a small bush might look identical from above – SAM 3 might confuse them.
Extreme viewing angles: Drones sometimes take photos from an angle, not straight down. SAM 3 was trained mostly on nadir (straight down) views, so angled views reduce accuracy.
Sensor noise: Very noisy images (from old satellites) confuse the model.
Unusual spectral bands: If your image uses infrared or other non-RGB bands, SAM 3 won’t know what to do with them.
For extreme cases, fine-tuning on your specific conditions is the best path. With just 20-30 examples, you can teach SAM 3 to handle your unique challenges.
Conclusion: SAM 3 is built for the real world
When you compare SAM 3 vs SAM for aerial segmentation in real-world conditions – clouds, shadows, crowds, seasons, different resolutions – the new model is clearly built to handle messiness. Its training on diverse data, presence head to avoid false alarms, and ability to separate crowded objects make it reliable when conditions aren’t perfect.
Want to see how SAM 3 performs on YOUR challenging images? Read our full case study with disaster response examples and tips for difficult conditions: SAM 3 vs SAM for aerial segmentation – real-world performance by Labellerr AI. We show you exactly how to get good results even when weather, shadows, or crowds make mapping difficult. Start handling real-world conditions today
!